This article shows how to make a graph showing a Linux machine’s CPU frequency changes. This plugin gathers CPU Frequency of all the virtual processors aka cores. In general, this module collects simple data for the processors’ frequencies like the Linux command of showing the number in /sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq. The purpose of this article is to make a graph showing CPU frequency changes, which may be a hit for CPU load on the system.
The Linux machine is using collectd to gather CPU frequency statistics and send them to the time series back-end – InfluxDB. Grafana is used to visualize the data stored in the time series back-end InfluxDB and organize the graphs in panels and dashboards. Check out the previous articles on the subject to install and configure such software to collect, store and visualize data – Monitor and analyze with Grafana, influxdb 1.8 and collectd under CentOS Stream 9, Monitor and analyze with Grafana, influxdb 1.8 and collectd under Ubuntu 22.04 LTS and Create graph for Linux CPU usage using Grafana, InfluxDB and collectd
The collectd daemon is used to gather data on the Linux system and to send it to the back-end InfluxDB.
Key knowledge for the cpufreq collectd plugin
- The collectd plugin cpufreq official page – https://collectd.org/wiki/index.php/Plugin:CPUFreq
- The CPUFreq plugin options – https://collectd.org/documentation/manpages/collectd.conf.5.shtml#plugin_cpufreq There are no options for this plugin, at present.
- to enable the CPUFreq plugin, load the plugin with the load directive in /etc/collectd.conf
LoadPlugin cpufreq
- The CPUFreq plugin collects data every 10 seconds.
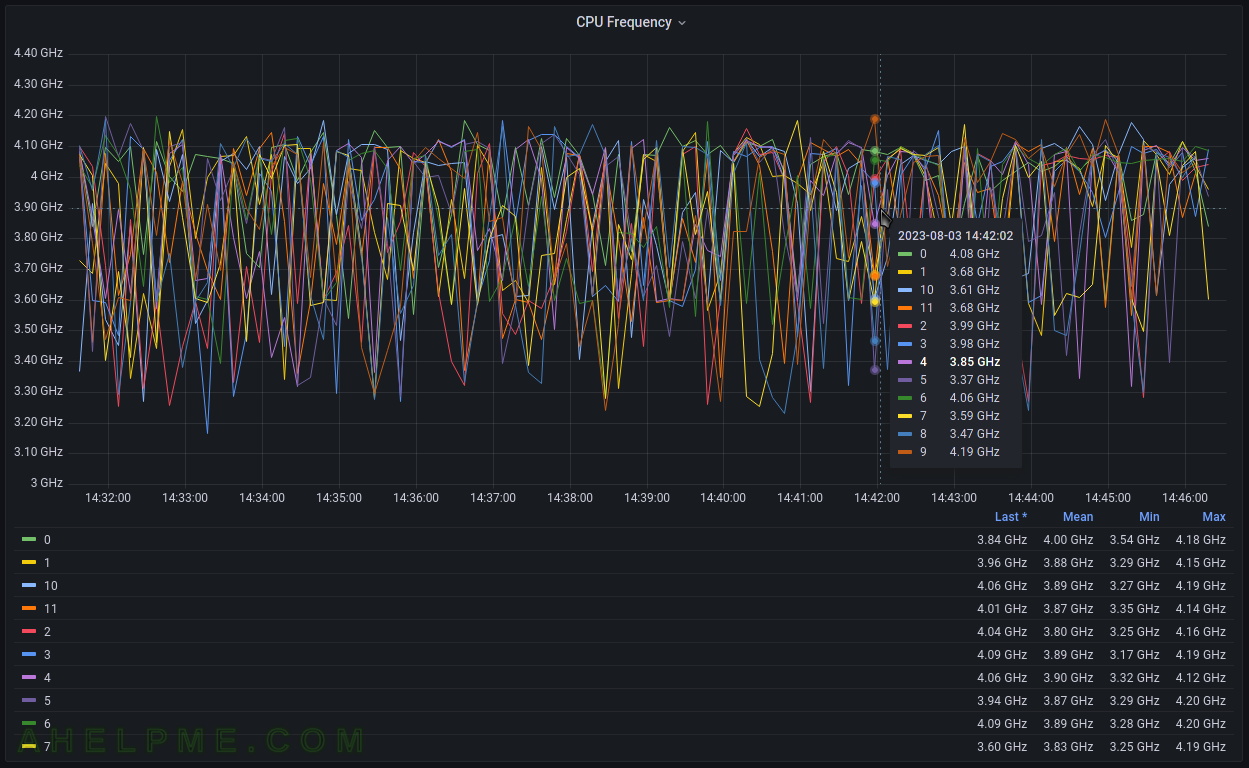
- cpufreq_value – a single Gauge value – a metric, which value that can go up and down. It is used to store the current CPU (or core)frequency. So there are multiple gauge values with different tags for the different cores (processors).
tag key tag value description host server hostname The name of the source this measurement was recorded. type cpufreq The current frequency of the current processor or the current core. instance processors/cores ids The processors (or cores) starting from 0 to N. - A Gauge value – a metric, which value that can go up and down. More on the topic – Data sources.
A GAUGE value is simply stored as-is. This is the right choice for values which may increase as well as decrease, such as temperatures or the amount of memory used, frequencies, etc.
- To cross-check the value, the user can use the /sys/devices/system/cpu/cpu*/cpufreq/scaling_cur_freq and replacing the * with integer number like 0, 1, 2, etc.
[root@srv ~]# cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_cur_freq 4161945 4184149 4062907 4044231 4183620 4107467 4187644 4167952
The values are in Hz for the each virtual processor shown in /proc/cpuinfo under a Linux system.
The InfluxQL query for the Linux cpufreq plugin is grouped by the processors’ ids (0, 1, 2, 3, etc.)
The query is Grafana generated.
SELECT mean("value") FROM "cpufreq_value" WHERE ("host" = 'srv2' AND "type" = 'cpufreq') AND $timeFilter GROUP BY time($__interval), "instance" fill(null)
The mean function will compute the mean if there is more than one value in the database for every 10 minutes (this is the “group by” logic here). Probably the most accurate query might be to use the last() function instead of mean() and to group by time(10s) (or the time interval, of which the data is written in the database). As mentioned above, the collectd interval is 10 seconds.
SCREENSHOT 1) Create a new dashboard, which will contain the CPU Frequency graph.
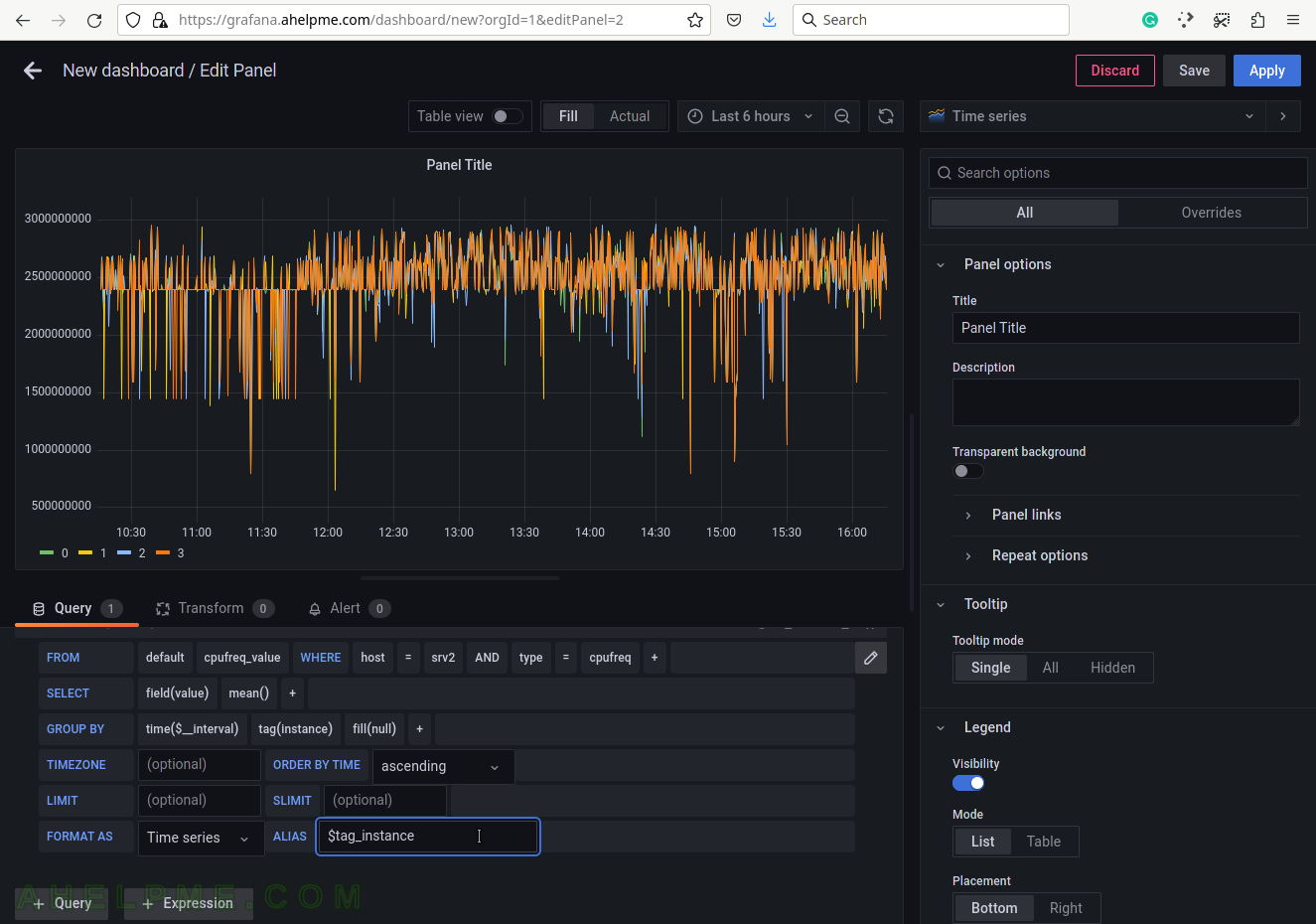
SCREENSHOT 2) Add a new panel in the new dashboard, which will contain the CPU Frequency graph.
SCREENSHOT 3) Change the “Data Source” to the collectd (InfluxDB) database and ensure on the right top the graph type is “Time series”.
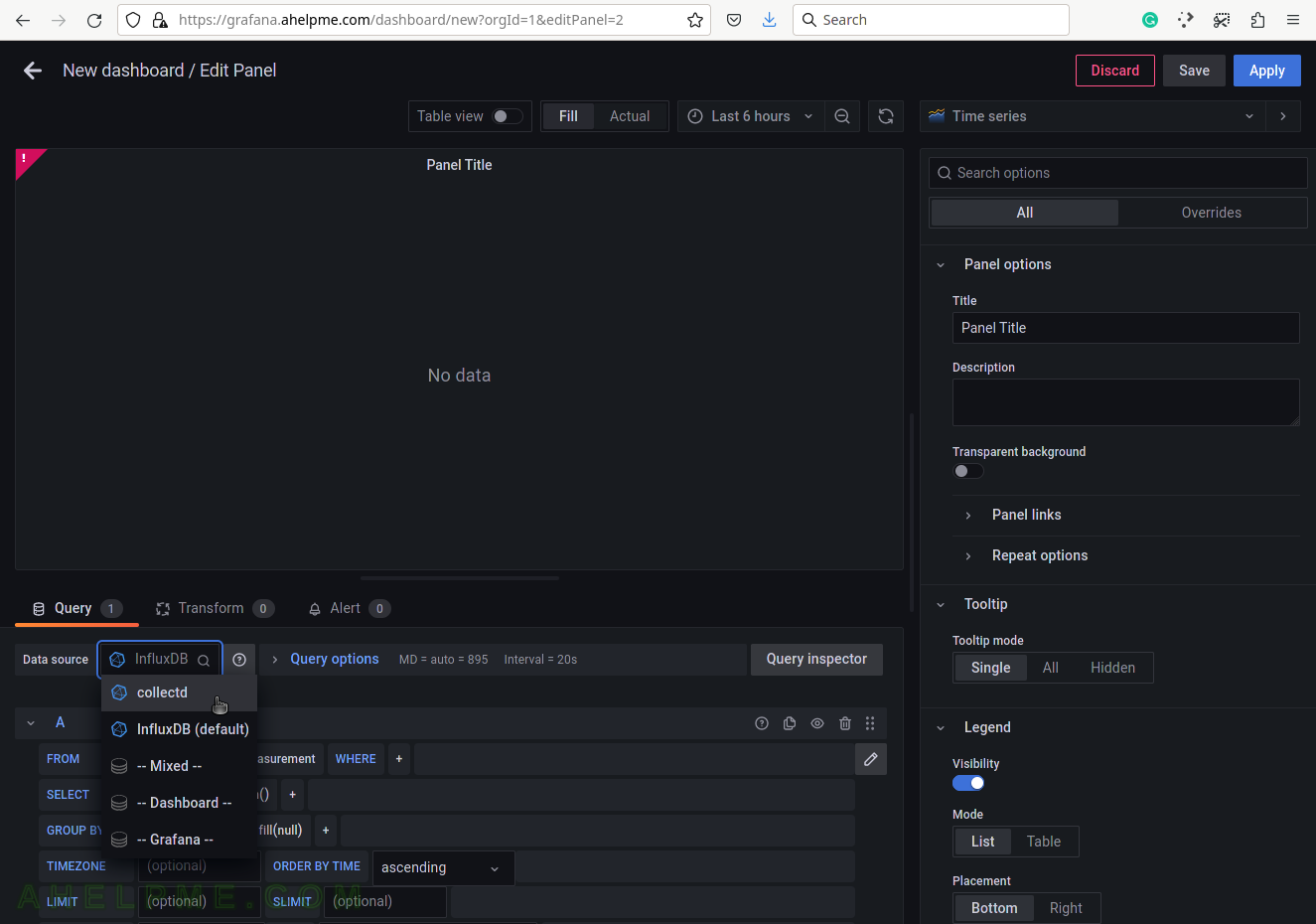
SCREENSHOT 4) Choose the cpufreq_value from the measurement drop-down list.
There are all measurements in the drop-down list in the database collectd.
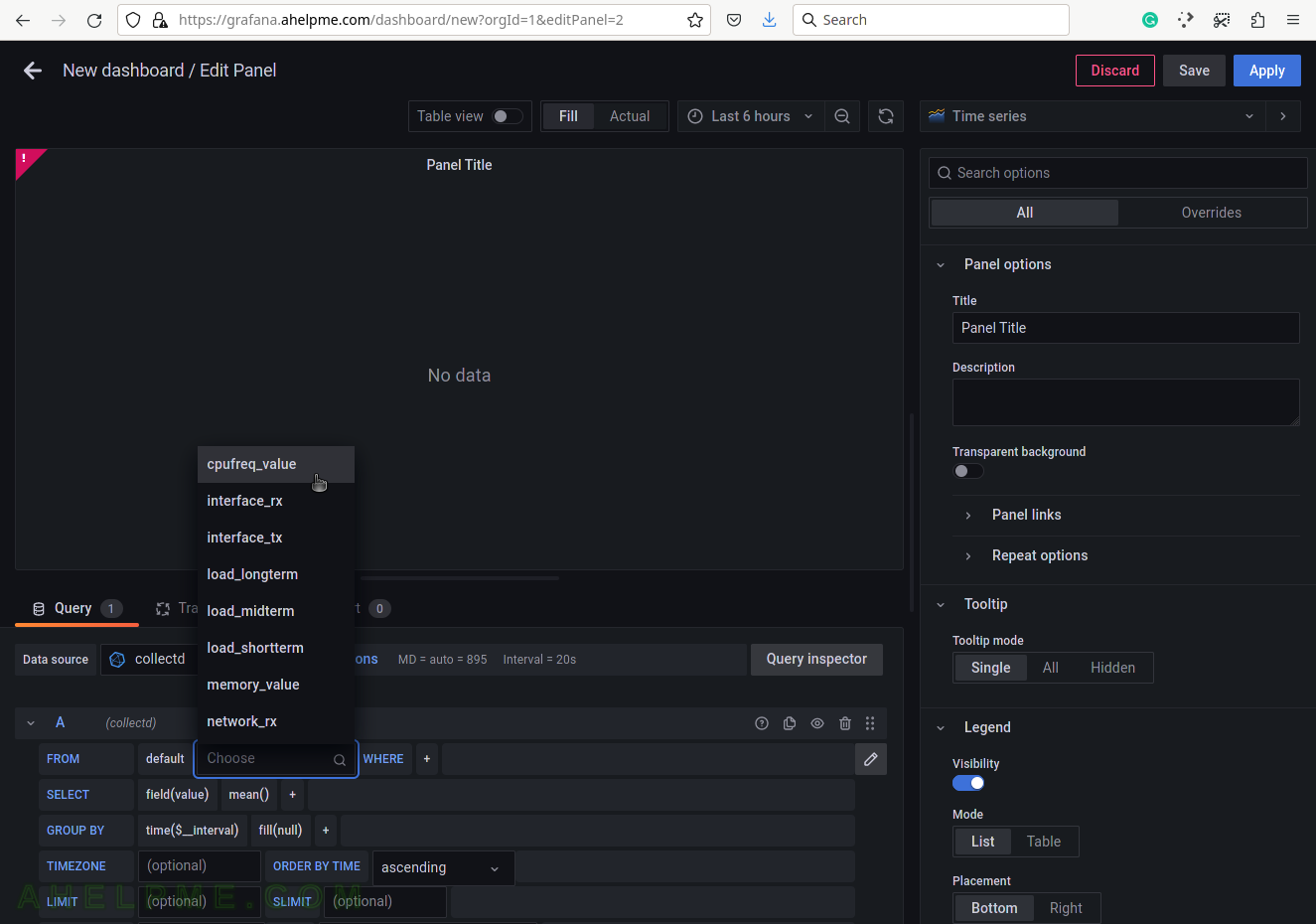
SCREENSHOT 5) Select the tag name “host” to limit the query for a selected hostname.
A tag is a key-value pair, which represents the metadata of a measurement record. For example, a measurement record consists of the actual measurement value and metadata for it such as which did the measurement and where. The server hostname “srv2” is the tag value and the tag key is the “host” name of the tag.
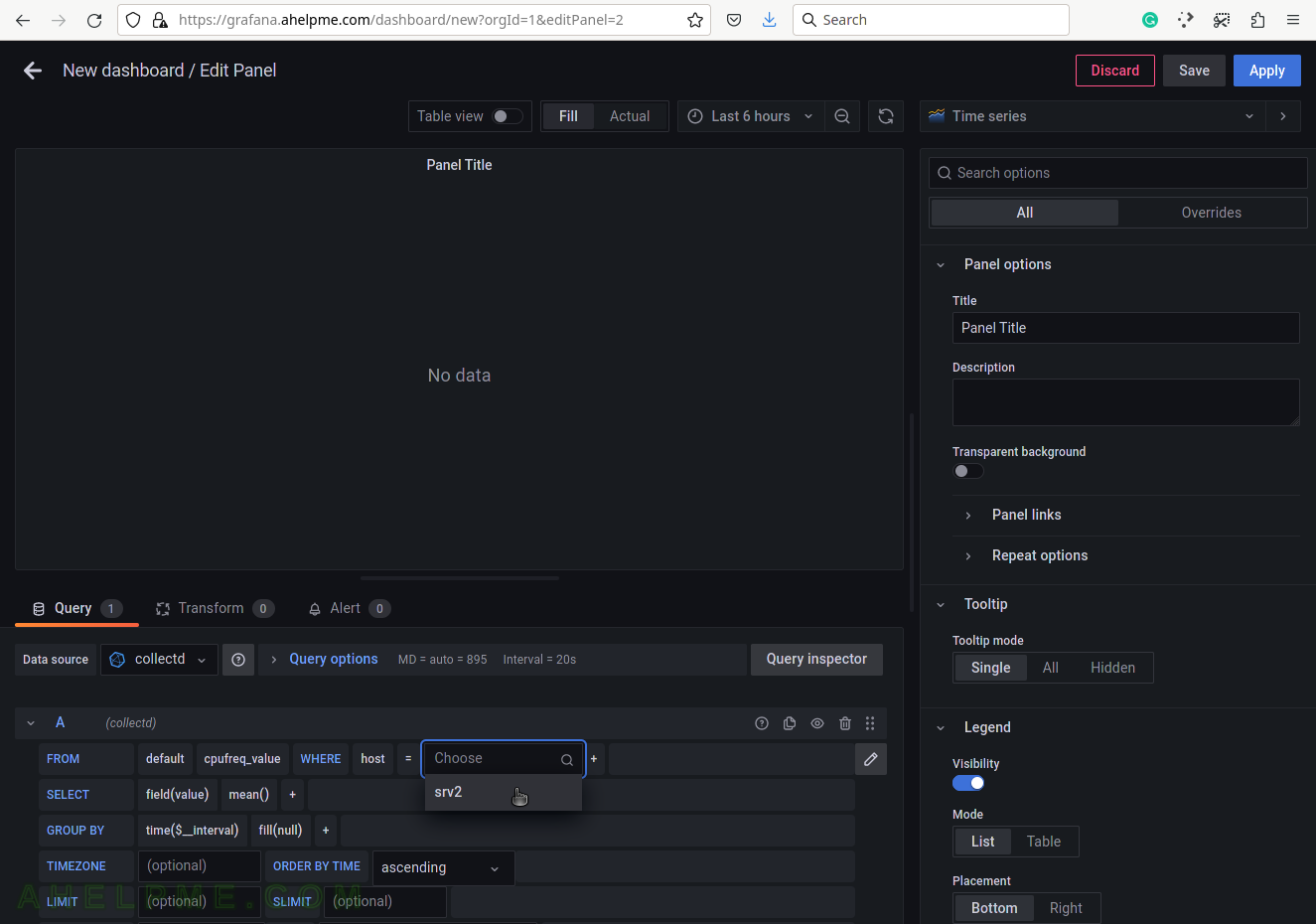
SCREENSHOT 6) Select the tag value “srv2”.
This setup has only one server, so no other servers’ hostnames are shown.
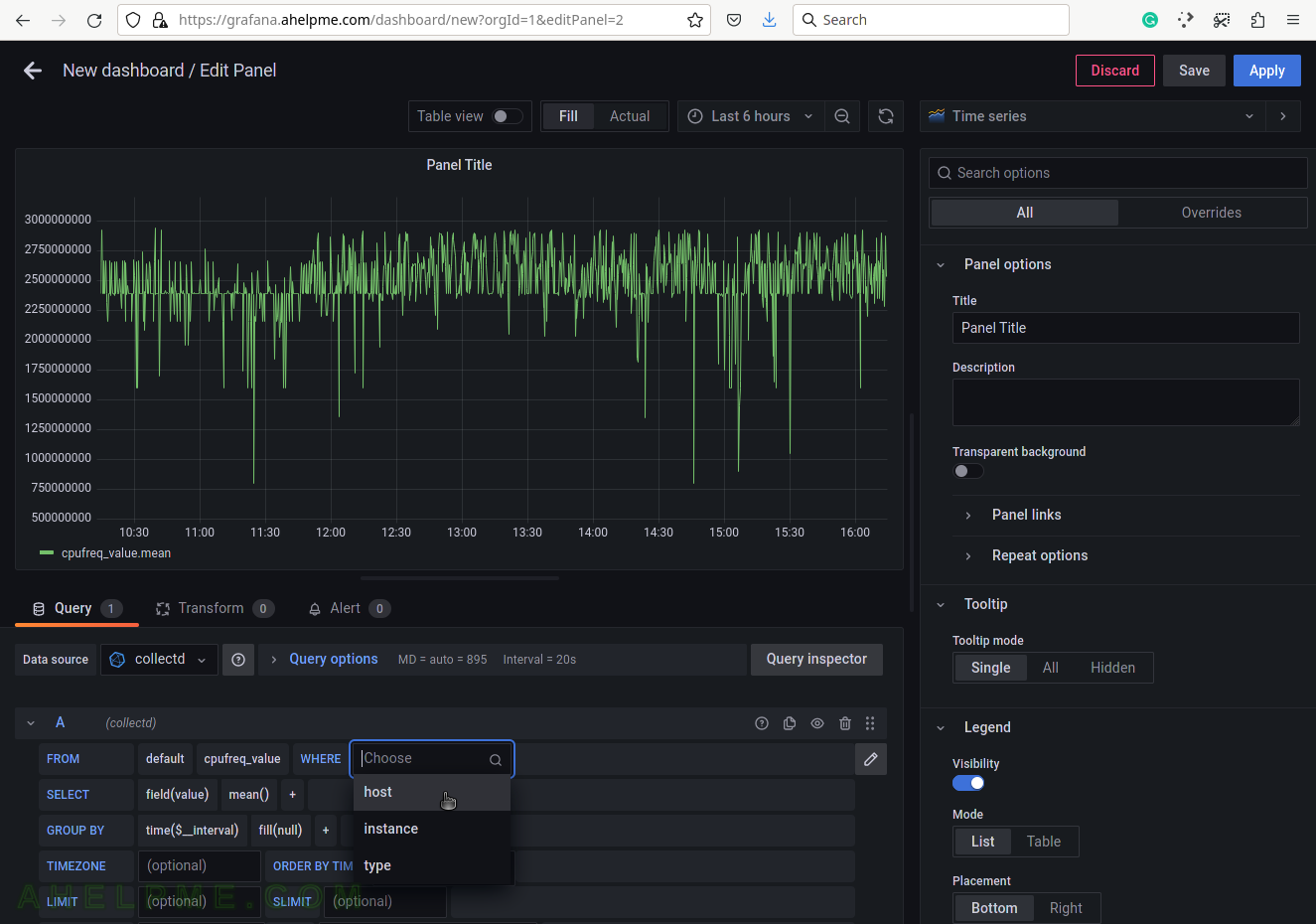
SCREENSHOT 7) Select the type of measurement.
Yet another measurement metadata. The type of measurement is cpufreq, i.e. cpu/cores/virtual processors frequencies.
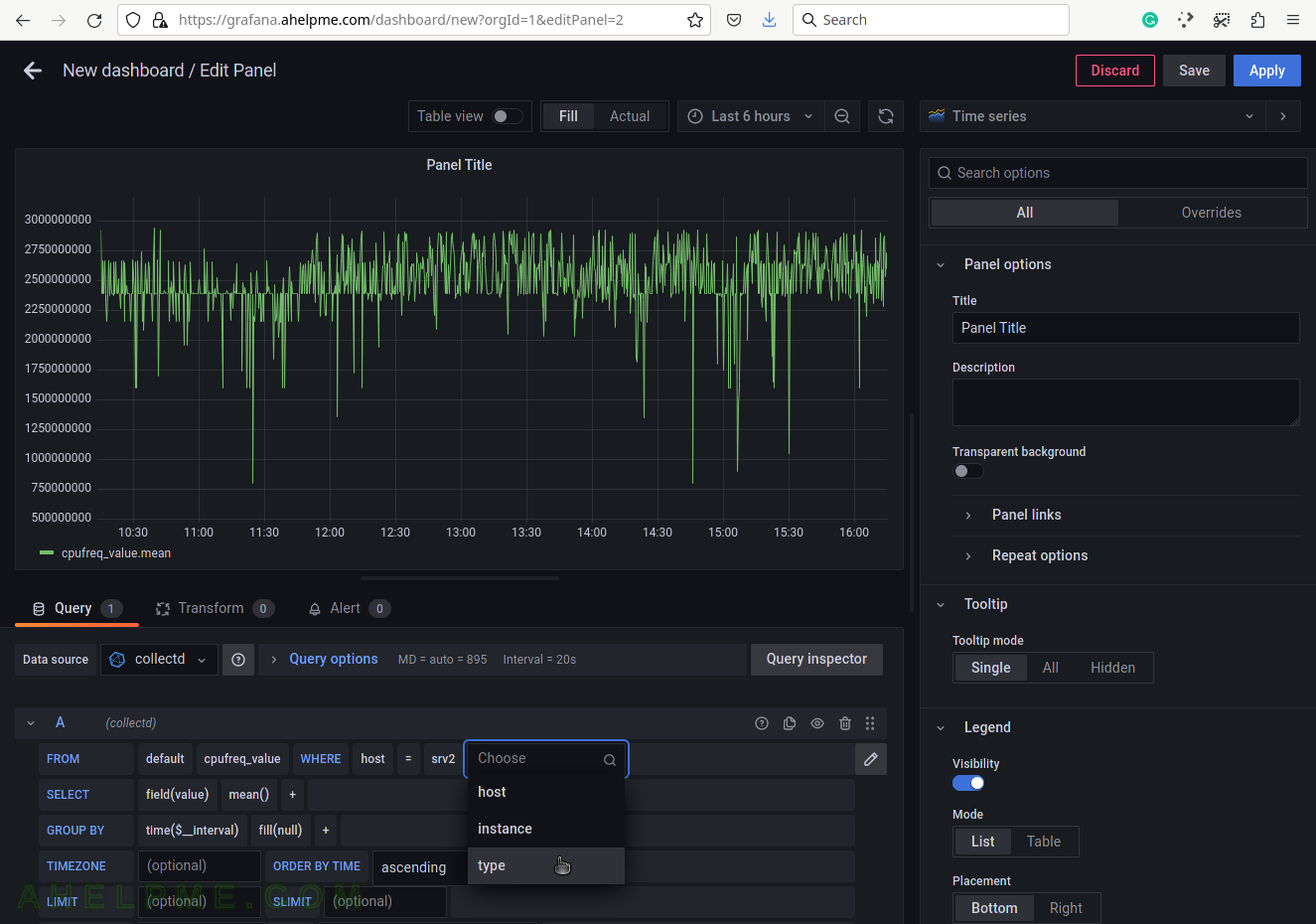
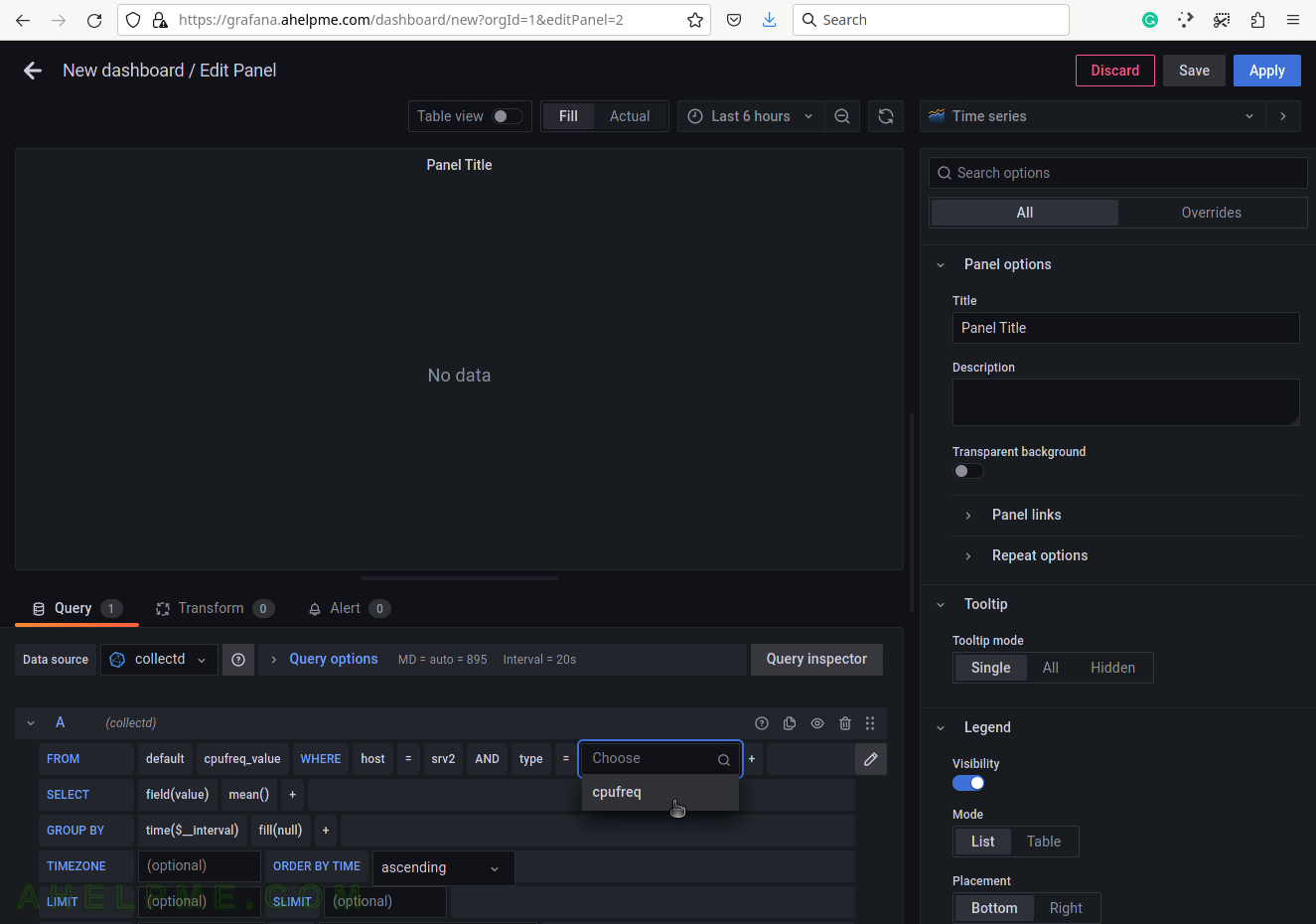
SCREENSHOT 8) Select cpufreq for the tag value to draw cpu frequency in the graph.
SCREENSHOT 9) Add a group by tag_instance to split the different tags in the graph.
The tag_instance shows the cores/processors of the system, which could be: 0, 1, 2, 3. All available processors/cores will be included starting from 0 to N.
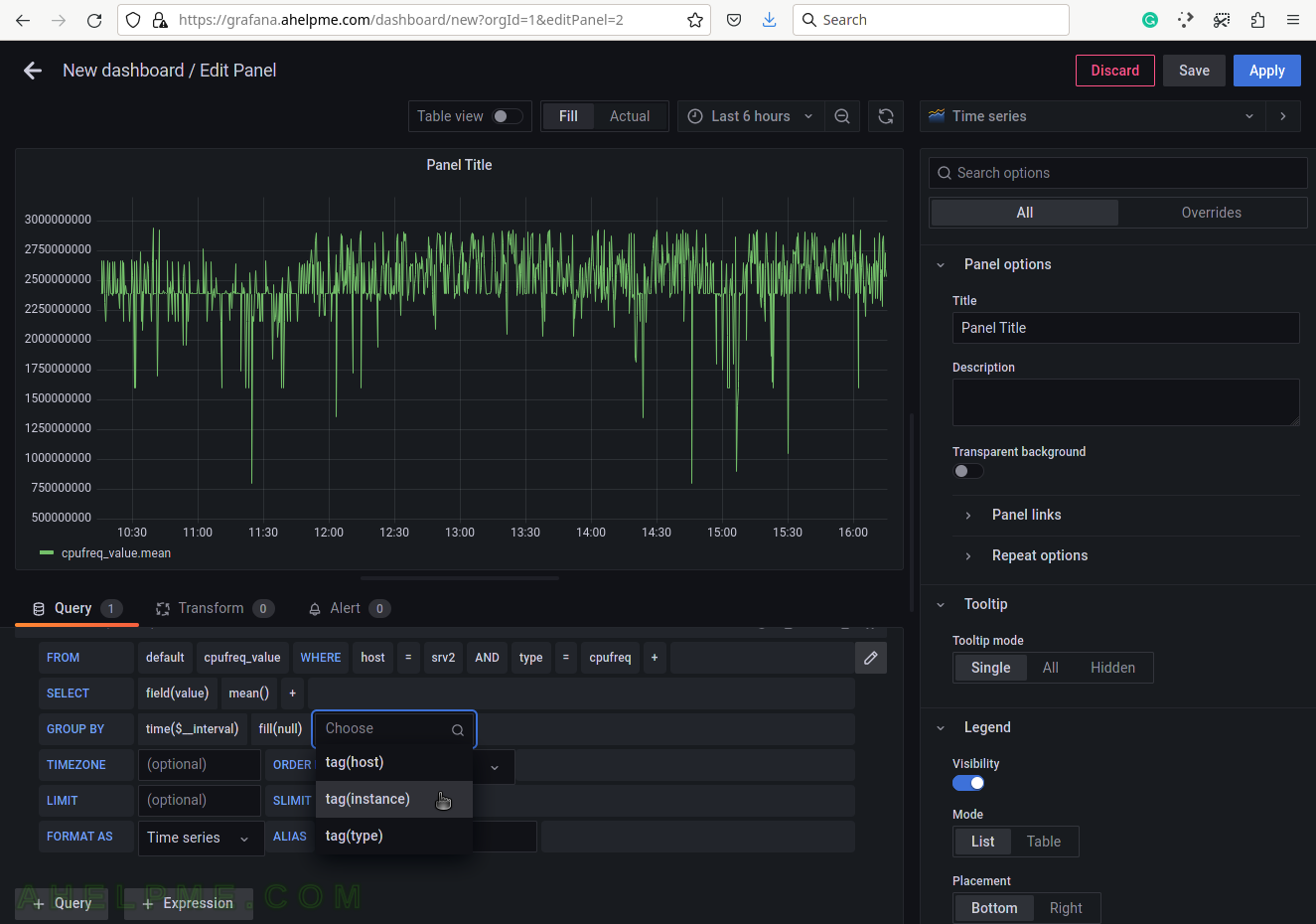
SCREENSHOT 10) To give pretty names to the tags in the graph’s legend add to the ALIAS a variable $tag_[tag_key] and in this case, the tag key is instance so that the variable will be $tag_instance.
There is an important variable “$__interval“, which may be edited and set to the rate of the original data (if applicable, not really for the cpufreq) or left as is to be computed each time based on the selected time frame of the graph (6 hours for this example).