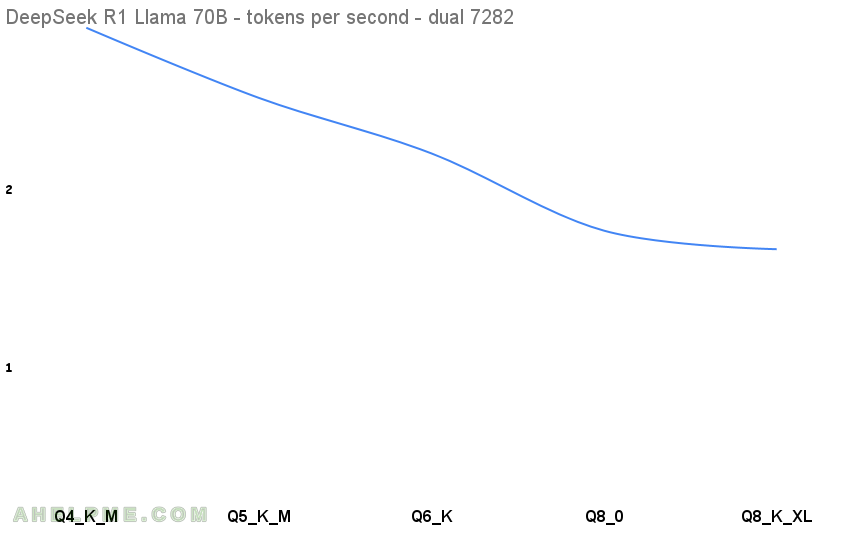
This article shows the CPU-only inference with a relatively old server processor – AMD Epyc 7282. For the LLM model the DeepSeek R1 Distill Llama 70B with different quantization are used to show the difference in token generation per second and memory consumption. DeepSeek R1 Distill Llama 70B is a pretty solid LLM model, which can successfully replace the current paid LLM options. The article is focused only showing the benchmark of the LLM tokens generations per second and there are other papers on the quality of the output for the different quantized version. Servers with the first and second generation of AMD CPUs with 16 or 32 cores are really cheap in the after market, but here are the LLM token generation speed ones could get. Such systems could be used to run them, but the token generation speed is unusable with around of 2.8 tokens per second from the Q4 numbers.
The testing bench is:
- Dual sockets AMD EPYC 7282 CPU – total 32 core CPU / 64 threads
- 128GB RAM in 8 channel, all 8 CPU channels are populated with 8GB DDR4 3200MHz Samsung for each CPU, total of 128G (2x8x8G).
- Supermicro H11DSU-iN Series motherboard
- Testing with LLAMA.CPP – llama-bench
- theoretical memory bandwidth 160 GB/s (per 80G for CPU socket for this CPU, according to the official documents form AMD). Real memory bandwidth 130Gb/s (more on here).
- the context window is the default 4K of the llama-bench tool. The memory consumption could vary greatly if context window is increased.
- More information for the setup and benchmarks – LLM inference benchmarks with llamacpp and AMD EPYC 7282 CPU
Here are the results. The first benchmark test is Q4 and is used as a baseline for the diff column below, because Q4 are really popular and they offer a good quality and really small footprint related to the full sized model version. Unfortunately, the DeepSeek R1 Distill Llama F16 (16 bit numbers) needs more than 128G RAM, just 5-10G more, but the memory configuration should be really different 16x16G for maximum performance.
| N | model | parameters | quantization | memory | diff t/s % | tokens/s |
|---|---|---|---|---|---|---|
| 1 | DeepSeek R1 Distill Llama | 70B | Q4_K_M | 39.59 GiB | 0 | 2.844 |
| 2 | DeepSeek R1 Distill Llama | 70B | Q5_K_M | 46.51 GiB | 13.85 | 2.45 |
| 3 | DeepSeek R1 Distill Llama | 70B | Q6_K | 53.91 GiB | 12.73 | 2.138 |
| 4 | DeepSeek R1 Distill Llama | 70B | Q8_0 | 69.82 GiB | 20.18 | 1.704 |
| 5 | DeepSeek R1 Distill Llama | 70B | Q8_K_XL | 75.65 GiB | 6.10 | 1.6 |
| 6 | DeepSeek R1 Distill Llama | 70B | F16 | – | – | – |
The difference between the Q4 and Q8 in the tokens per second is 43.74% speed degradation, but the problem is even the Q4 is below 3 tokens per second is really slow. The F16 needs more memory than 128G RAM to be tested, but it might be around or even below 1 tokens per seconds on this system.
Here are all the tests output:
1. DeepSeek R1 Distill Llama 70B Q4_K_M
Using unsloth DeepSeek-R1-Distill-Llama-70B-Q4_K_M.gguf file.
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 32 -p 0 -n 128,256,512,1024,2048 -m /root/models/tests/DeepSeek-R1-Distill-Llama-70B-Q4_K_M.gguf | model | size | params | backend | threads | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | -------------------: | | llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | BLAS,RPC | 32 | tg128 | 2.88 ± 0.00 | | llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | BLAS,RPC | 32 | tg256 | 2.87 ± 0.00 | | llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | BLAS,RPC | 32 | tg512 | 2.86 ± 0.00 | | llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | BLAS,RPC | 32 | tg1024 | 2.82 ± 0.00 | | llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | BLAS,RPC | 32 | tg2048 | 2.79 ± 0.00 | build: 51f311e0 (4753)
2. DeepSeek R1 Distill Llama 70B Q5_K_M
Using unsloth DeepSeek-R1-Distill-Llama-70B-Q5_K_M.gguf file.
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 32 -p 0 -n 128,256,512,1024,2048 -m /root/models/tests/DeepSeek-R1-Distill-Llama-70B-Q5_K_M.gguf | model | size | params | backend | threads | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | -------------------: | | llama 70B Q5_K - Medium | 46.51 GiB | 70.55 B | BLAS,RPC | 32 | tg128 | 2.48 ± 0.00 | | llama 70B Q5_K - Medium | 46.51 GiB | 70.55 B | BLAS,RPC | 32 | tg256 | 2.47 ± 0.00 | | llama 70B Q5_K - Medium | 46.51 GiB | 70.55 B | BLAS,RPC | 32 | tg512 | 2.47 ± 0.00 | | llama 70B Q5_K - Medium | 46.51 GiB | 70.55 B | BLAS,RPC | 32 | tg1024 | 2.44 ± 0.00 | | llama 70B Q5_K - Medium | 46.51 GiB | 70.55 B | BLAS,RPC | 32 | tg2048 | 2.39 ± 0.00 | build: 51f311e0 (4753)
3. DeepSeek R1 Distill Llama 70B Q6_K
Using unsloth DeepSeek-R1-Distill-Llama-70B-Q6_K-00001-of-00002.gguf and DeepSeek-R1-Distill-Llama-70B-Q6_K-00002-of-00002.gguf files.
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 32 -p 0 -n 128,256,512,1024,2048 -m /root/models/tests/DeepSeek-R1-Distill-Llama-70B-Q6_K-00001-of-00002.gguf | model | size | params | backend | threads | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | -------------------: | | llama 70B Q6_K | 53.91 GiB | 70.55 B | BLAS,RPC | 32 | tg128 | 2.16 ± 0.00 | | llama 70B Q6_K | 53.91 GiB | 70.55 B | BLAS,RPC | 32 | tg256 | 2.16 ± 0.00 | | llama 70B Q6_K | 53.91 GiB | 70.55 B | BLAS,RPC | 32 | tg512 | 2.15 ± 0.00 | | llama 70B Q6_K | 53.91 GiB | 70.55 B | BLAS,RPC | 32 | tg1024 | 2.13 ± 0.00 | | llama 70B Q6_K | 53.91 GiB | 70.55 B | BLAS,RPC | 32 | tg2048 | 2.09 ± 0.00 | build: 51f311e0 (4753)
4. DeepSeek R1 Distill Llama 70B Q8_0
Using unsloth DeepSeek-R1-Distill-Llama-70B-Q8_0-00001-of-00002.gguf and DeepSeek-R1-Distill-Llama-70B-Q8_0-00002-of-00002.gguf files.
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 32 -p 0 -n 128,256,512,1024,2048 -m /root/models/tests/DeepSeek-R1-Distill-Llama-70B-Q8_0-00001-of-00002.gguf | model | size | params | backend | threads | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | -------------------: | | llama 70B Q8_0 | 69.82 GiB | 70.55 B | BLAS,RPC | 32 | tg128 | 1.72 ± 0.00 | | llama 70B Q8_0 | 69.82 GiB | 70.55 B | BLAS,RPC | 32 | tg256 | 1.72 ± 0.00 | | llama 70B Q8_0 | 69.82 GiB | 70.55 B | BLAS,RPC | 32 | tg512 | 1.71 ± 0.00 | | llama 70B Q8_0 | 69.82 GiB | 70.55 B | BLAS,RPC | 32 | tg1024 | 1.70 ± 0.00 | | llama 70B Q8_0 | 69.82 GiB | 70.55 B | BLAS,RPC | 32 | tg2048 | 1.67 ± 0.00 | build: 51f311e0 (4753)
5. DeepSeek R1 Distill Llama 70B Q8_K_XL
Using unsloth DeepSeek-R1-Distill-Llama-70B-UD-Q8_K_XL-00001-of-00002.gguf and DeepSeek-R1-Distill-Llama-70B-UD-Q8_K_XL-00002-of-00002.gguf files.
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 32 -p 0 -n 128,256,512,1024,2048 -m /root/models/tests/DeepSeek-R1-Distill-Llama-70B-UD-Q8_K_XL-00001-of-00002.gguf | model | size | params | backend | threads | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | -------------------: | | llama 70B Q8_0 | 75.65 GiB | 70.55 B | BLAS,RPC | 32 | tg128 | 1.61 ± 0.00 | | llama 70B Q8_0 | 75.65 GiB | 70.55 B | BLAS,RPC | 32 | tg256 | 1.61 ± 0.00 | | llama 70B Q8_0 | 75.65 GiB | 70.55 B | BLAS,RPC | 32 | tg512 | 1.61 ± 0.00 | | llama 70B Q8_0 | 75.65 GiB | 70.55 B | BLAS,RPC | 32 | tg1024 | 1.60 ± 0.00 | | llama 70B Q8_0 | 75.65 GiB | 70.55 B | BLAS,RPC | 32 | tg2048 | 1.57 ± 0.00 | build: 51f311e0 (4753)
Before all tests the cleaning cache commands were executed:
echo 0 > /proc/sys/kernel/numa_balancing echo 3 > /proc/sys/vm/drop_caches