For the LLM model the Alibaba’s Qwen3 Coder 30B A3B with different quantization are used to show the difference in token generation per second and memory consumption. Qwen3 Coder 30B A3B is an interesting LLM model, which main target is the software engineers and the tools they use for advanced auto-completion and code assistant. It is published by the Alibaba giant, and in many cases it can be considered to offload some LLM work locally for free, especially IT. The model is MoE (Mixture of Experts) with 30B total parameters and 128 experts, and 3.3B activated parameters and 8 activated experts. Bare in mind, the idea of this model is to be small and fast alternative to the bigger one – Qwen3-Coder-480B-A35B-Instruct, which is really big LLM with 300 GiB memory for the Q4 at least, but fighting with the very expensive Claude 4. The Qwen3 Coder 30B A3B is light-weight and fast model, which with enough context data may result in strong code assistant help in the IT. The article is focused only showing the benchmark of the LLM tokens generations per second and there are other papers on the quality of the output for the different quantized version. This model is ideal for auto-local completion service with a single low cost card like AMD Radeon Instinct Mi50 32Gb – not so old enterprise card, which could live for a couple of more years at home lab. At present, this card has GPU 32Gb fast memory for only around 200-250$. Building a low cost, but with good inference performance workstation is possible with couple of theses cards. Here are the speed and the use can expect. This article includes a BF16 (brain floating point) of the model using dual AMD Radeon Instinct Mi50 32Gb (to load the whole model in the GPU memory), all other tests are with a single card.
The testing bench is:
- Single GPU AMD Radeon Instinct Mi50 32Gb – 3840 cores
- 32GB RAM HBM2, with 4096 bit bus width.
- Test server – Gigabyte MS73-HB1 with dual XEON 8480+.
- Link Speed 16GT/s, Width x16
- Testing with LLAMA.CPP – llama-bench
- theoretical memory bandwidth 1.02 TB/s (according to the official documents from AMD)
- the context window is the default 4K of the llama-bench tool. The memory consumption could vary greatly if context window is increased.
- Price: around $250 in ebay.com (Q4 2025).
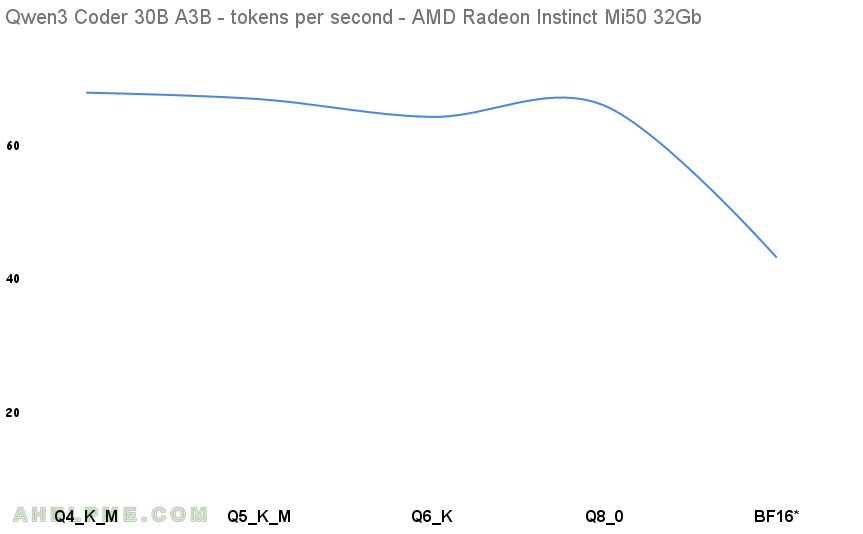
Here are the results. The first benchmark test is Q4 and is used as a baseline for the diff column below, because Q4 are really popular and they offer a good quality and really small footprint related to the full sized model version.
| N | model | parameters | quantization | memory | diff t/s % | tokens/s |
|---|---|---|---|---|---|---|
| 1 | Qwen3 Coder 30B A3B | 30.53 B | Q4_K_M | 17.28 GiB | 0 | 66.114 |
| 2 | Qwen3 Coder 30B A3B | 30.53 B | Q5_0 | 20.23 GiB | 1.45 | 65.152 |
| 3 | Qwen3 Coder 30B A3B | 30.53 B | Q6_K | 23.36 GiB | 4.09 | 62.486 |
| 4 | Qwen3 Coder 30B A3B | 30.53 B | Q8_0 | 30.25 GiB | -2.73 | 64.198 |
| 5* | Qwen3 Coder 30B A3B | 30.53 B | BF16 | *56.89 GiB | 35.49 | 41.408 |
It’s worth noting when the total output tokens increase, the tokens per second also might decrease significantly (which is valid for all GPUs/CPUs, not only for this one)! So the above table with numbers are the expected performance for the desired total output size of the tests below taking the average between 128,256,512,1024 and 2048 tokens.
The difference between the Q4 and BF16 in the tokens per second is 37.36% speed degradation and even the BF16 (brain floating point) with two cards is usable with tokens generation around 20 per second. Around 15 tokens per second is good and usable for daily use for a single user, which is what the GPU inference would offer easily.
Here are all the tests output:
1. Qwen3 Coder 30B A3B Q4_K_M
Using unsloth Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf file..
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 112 -ngl 99 -p 0 -n 128,256,512,1024,2048 -m /root/models/unsloth/Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 ROCm devices: Device 0: AMD Radeon Graphics, gfx906:sramecc+:xnack- (0x906), VMM: no, Wave Size: 64 | model | size | params | backend | ngl | threads | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | ------: | --------------: | -------------------: | | qwen3moe 30B.A3B Q4_K - Medium | 17.28 GiB | 30.53 B | ROCm,RPC | 99 | 56 | tg128 | 73.10 ± 0.07 | | qwen3moe 30B.A3B Q4_K - Medium | 17.28 GiB | 30.53 B | ROCm,RPC | 99 | 56 | tg256 | 71.10 ± 0.03 | | qwen3moe 30B.A3B Q4_K - Medium | 17.28 GiB | 30.53 B | ROCm,RPC | 99 | 56 | tg512 | 66.69 ± 2.64 | | qwen3moe 30B.A3B Q4_K - Medium | 17.28 GiB | 30.53 B | ROCm,RPC | 99 | 56 | tg1024 | 63.80 ± 0.01 | | qwen3moe 30B.A3B Q4_K - Medium | 17.28 GiB | 30.53 B | ROCm,RPC | 99 | 56 | tg2048 | 55.88 ± 0.04 | build: 128d522c (6686)
2. Qwen3 Coder 30B A3B Q5_K_M
.Using unsloth Qwen3-Coder-30B-A3B-Instruct-Q5_K_M.gguf file.
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 112 -ngl 99 -p 0 -n 128,256,512,1024,2048 -m /root/models/unsloth/Qwen3-Coder-30B-A3B-Instruct-Q5_K_M.gguf ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 ROCm devices: Device 0: AMD Radeon Graphics, gfx906:sramecc+:xnack- (0x906), VMM: no, Wave Size: 64 | model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | --------------: | -------------------: | | qwen3moe 30B.A3B Q5_K - Medium | 20.23 GiB | 30.53 B | ROCm,RPC | 99 | tg128 | 71.25 ± 0.23 | | qwen3moe 30B.A3B Q5_K - Medium | 20.23 GiB | 30.53 B | ROCm,RPC | 99 | tg256 | 69.61 ± 0.10 | | qwen3moe 30B.A3B Q5_K - Medium | 20.23 GiB | 30.53 B | ROCm,RPC | 99 | tg512 | 67.27 ± 0.04 | | qwen3moe 30B.A3B Q5_K - Medium | 20.23 GiB | 30.53 B | ROCm,RPC | 99 | tg1024 | 62.69 ± 0.02 | | qwen3moe 30B.A3B Q5_K - Medium | 20.23 GiB | 30.53 B | ROCm,RPC | 99 | tg2048 | 54.94 ± 0.04 | build: 128d522c (6686)
3. Qwen3 Coder 30B A3B Q6_K
Using unsloth Qwen3-Coder-30B-A3B-Instruct-Q6_K.gguf file.
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 112 -ngl 99 -p 0 -n 128,256,512,1024,2048 -m /root/models/unsloth/Qwen3-Coder-30B-A3B-Instruct-Q6_K.gguf ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 ROCm devices: Device 0: AMD Radeon Graphics, gfx906:sramecc+:xnack- (0x906), VMM: no, Wave Size: 64 | model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | --------------: | -------------------: | | qwen3moe 30B.A3B Q6_K | 23.36 GiB | 30.53 B | ROCm,RPC | 99 | tg128 | 68.33 ± 0.04 | | qwen3moe 30B.A3B Q6_K | 23.36 GiB | 30.53 B | ROCm,RPC | 99 | tg256 | 66.61 ± 0.03 | | qwen3moe 30B.A3B Q6_K | 23.36 GiB | 30.53 B | ROCm,RPC | 99 | tg512 | 64.33 ± 0.02 | | qwen3moe 30B.A3B Q6_K | 23.36 GiB | 30.53 B | ROCm,RPC | 99 | tg1024 | 60.12 ± 0.04 | | qwen3moe 30B.A3B Q6_K | 23.36 GiB | 30.53 B | ROCm,RPC | 99 | tg2048 | 53.04 ± 0.04 | build: 128d522c (6686)
4. Qwen3 Coder 30B A3B Q8_0
Using unsloth Qwen3-Coder-30B-A3B-Instruct-Q8_0.gguf file.
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 112 -ngl 99 -p 0 -n 128,256,512,1024,2048 -m /root/models/unsloth/Qwen3-Coder-30B-A3B-Instruct-Q8_0.gguf ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 ROCm devices: Device 0: AMD Radeon Graphics, gfx906:sramecc+:xnack- (0x906), VMM: no, Wave Size: 64 | model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | --------------: | -------------------: | | qwen3moe 30B.A3B Q8_0 | 30.25 GiB | 30.53 B | ROCm,RPC | 99 | tg128 | 70.50 ± 0.28 | | qwen3moe 30B.A3B Q8_0 | 30.25 GiB | 30.53 B | ROCm,RPC | 99 | tg256 | 68.62 ± 0.07 | | qwen3moe 30B.A3B Q8_0 | 30.25 GiB | 30.53 B | ROCm,RPC | 99 | tg512 | 66.14 ± 0.02 | | qwen3moe 30B.A3B Q8_0 | 30.25 GiB | 30.53 B | ROCm,RPC | 99 | tg1024 | 61.62 ± 0.02 | | qwen3moe 30B.A3B Q8_0 | 30.25 GiB | 30.53 B | ROCm,RPC | 99 | tg2048 | 54.11 ± 0.04 | build: 128d522c (6686)
5. Qwen3 Coder 30B A3B BF16
Using unsloth Qwen3-Coder-30B-A3B-Instruct-BF16-00001-of-00002.gguf and Qwen3-Coder-30B-A3B-Instruct-BF16-00002-of-00002.gguf files.
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 112 -ngl 99 -p 0 -n 128,256,512,1024,2048 -m /root/models/unsloth/Qwen3-Coder-30B-A3B-Instruct-BF16-00001-of-00002.gguf ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 2 ROCm devices: Device 0: AMD Radeon Graphics, gfx906:sramecc+:xnack- (0x906), VMM: no, Wave Size: 64 Device 1: AMD Radeon Graphics, gfx906:sramecc+:xnack- (0x906), VMM: no, Wave Size: 64 | model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | --------------: | -------------------: | | qwen3moe 30B.A3B BF16 | 56.89 GiB | 30.53 B | ROCm,RPC | 99 | tg128 | 44.06 ± 0.05 | | qwen3moe 30B.A3B BF16 | 56.89 GiB | 30.53 B | ROCm,RPC | 99 | tg256 | 42.80 ± 0.16 | | qwen3moe 30B.A3B BF16 | 56.89 GiB | 30.53 B | ROCm,RPC | 99 | tg512 | 42.60 ± 0.24 | | qwen3moe 30B.A3B BF16 | 56.89 GiB | 30.53 B | ROCm,RPC | 99 | tg1024 | 40.51 ± 0.32 | | qwen3moe 30B.A3B BF16 | 56.89 GiB | 30.53 B | ROCm,RPC | 99 | tg2048 | 37.07 ± 0.20 | build: 128d522c (6686)
Bear in mind that there is an additional latency because of the data transfer between the two cards using the PCI-E.
Many tokens output
When the output is large amount of tokens, the average speed of the tokens per second generation could degrade significantly. Here is a test with 16K tokens output and the performance is only 20 tokens per second for the Q4_K_M, even the 128 tokens output could reach above 70 tokens/sec!
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 112 -ngl 99 -p 0 -n 16384 -m /root/models/unsloth/Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 ROCm devices: Device 0: AMD Radeon Graphics, gfx906:sramecc+:xnack- (0x906), VMM: no, Wave Size: 64 | model | size | params | backend | ngl | threads | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | ------: | --------------: | -------------------: | | qwen3moe 30B.A3B Q4_K - Medium | 17.28 GiB | 30.53 B | ROCm,RPC | 99 | 56 | tg16384 | 20.79 ± 0.03 | build: 128d522c (6686)
In fact, with 32K tokens output the speed is only 10 tokens per second! Such speed degradation is valid for all kind GPU/CPU token generations, but system with more GPU cores degrades with lower percentages.
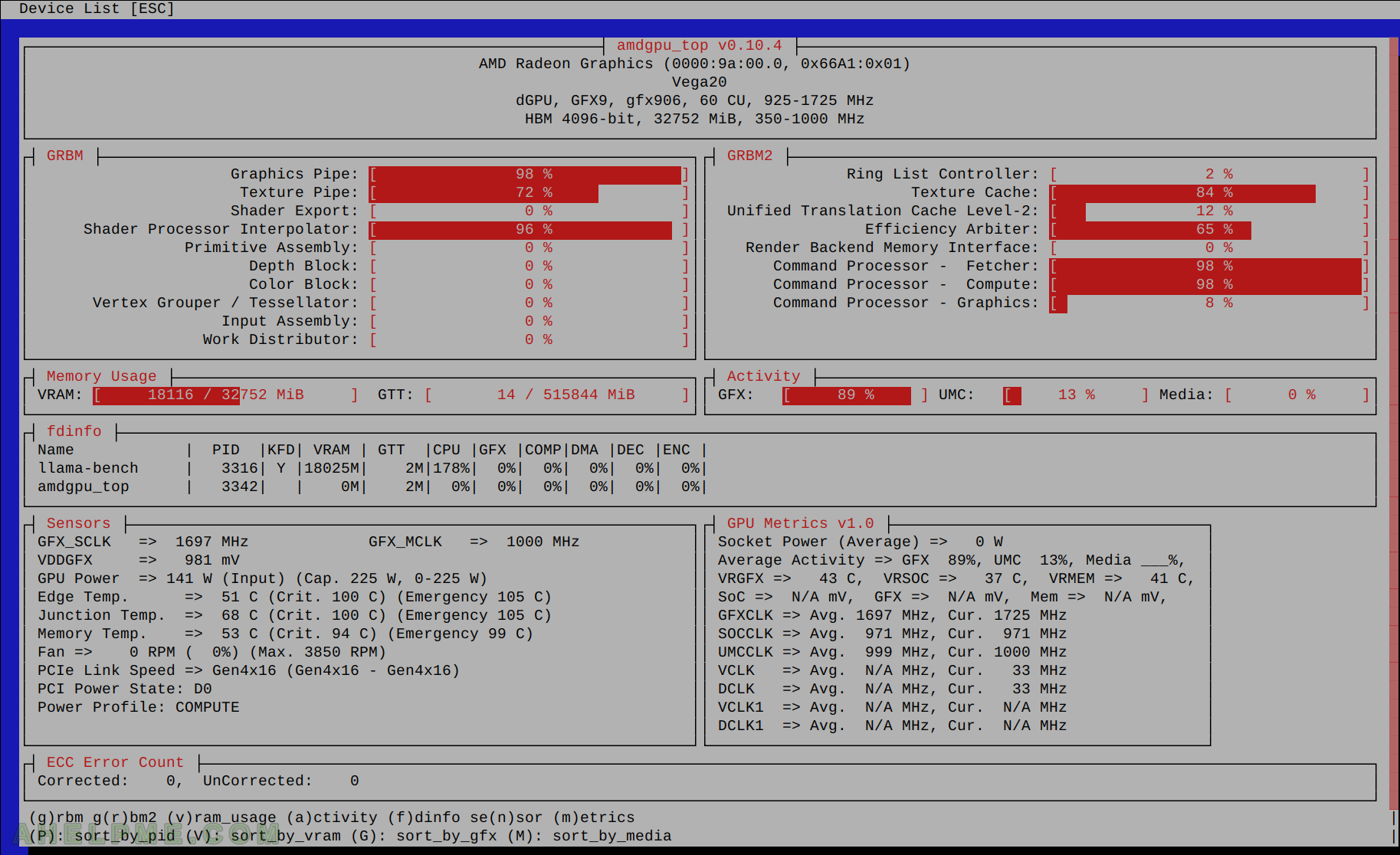
SCREENSHOT 1) The AMDGPU top utility with temperatures, GPU activity and memory usage.
The temperature is maximum 68C and the GPU card is not throttling in any of the tests.
Before all tests the cleaning cache commands were executed:
echo 0 > /proc/sys/kernel/numa_balancing echo 3 > /proc/sys/vm/drop_caches