This article shows the CPU-only inference with a modern server processor – AMD Epyc 9554. For the LLM model the Mistral Large Instruct 123B 2411 with different quantization are used to show the difference in token generation per second and memory consumption. Mistral Large Instruct 123B 2411 is a pretty solid LLM reasoning model, which can successfully replace the current paid LLM options. The article is focused only showing the benchmark of the LLM tokens generations per second and there are other papers on the quality of the output for the different quantized version. This LLM is a big one with 123B parameters, so it would need a lot of memory – 70GiB at least.
The testing bench is:
- Single socket AMD EPYC 9554 CPU – 64 core CPU / 128 threads
- 196GB RAM in 12 channel, all 12 CPU channels are populated with 16GB DDR5 5600MHz Samsung.
- ASUS K14PA-U24-T Series motherboard
- Testing with LLAMA.CPP – llama-bench
- theoretical memory bandwidth 460.8 GB/s (according to the official documents form AMD)
- the context window is the default 4K of the llama-bench tool. The memory consumption could vary greatly if context window is increased.
- More information for the setup and benchmarks – LLM inference benchmarks with llamacpp and AMD EPYC 9554 CPU
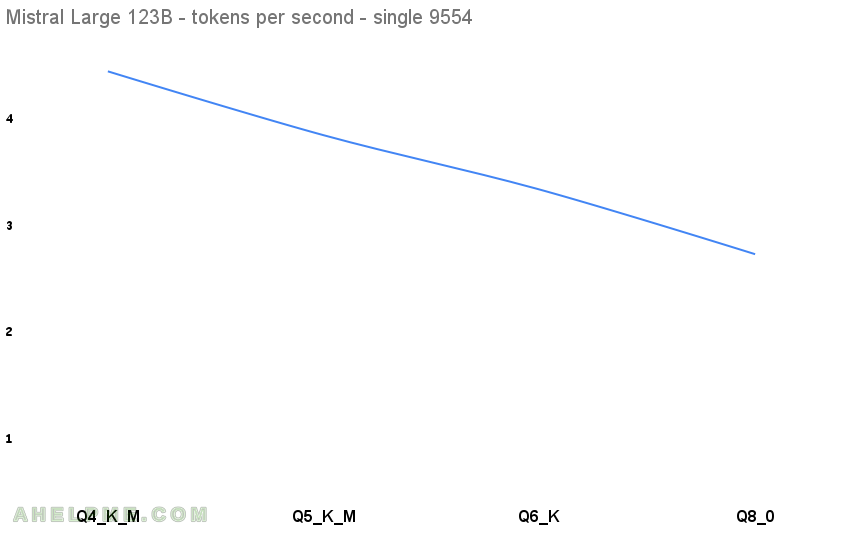
Here are the results. The first benchmark test is Q4 and is used as a baseline for the diff column below, because Q4 are really popular and they offer a good quality and really small footprint related to the full sized model version.
| N | model | parameters | quantization | memory | diff t/s % | tokens/s |
|---|---|---|---|---|---|---|
| 1 | Mistral Large Instruct 123B 2411 | 123B | Q4_K_M | 68.19 GiB | 0 | 4.332 |
| 2 | Mistral Large Instruct 123B 2411 | 123B | Q5_K_M | 80.55 GiB | 13.80 | 3.734 |
| 3 | Mistral Large Instruct 123B 2411 | 123B | Q6_K | 93.68 GiB | 13.60 | 3.226 |
| 4 | Mistral Large Instruct 123B 2411 | 123B | Q8_0 | 121.33 GiB | 18.78 | 2.62 |
The difference between the Q4 and Q8 in the tokens per second is 39.98% speed degradation, but the problem is that the tokens generation is slow even using Q4 – only around 4 tokens per second. Using this model on a such single CPU is possible, but is slow and probably usable only as a some kind of a reference or cross-check, not for daily work.
Here are all the tests output:
1. Mistral Large-Instruct 2411 Q4_K_M
Using bartowski Mistral-Large-Instruct-2411-Q4_K_M-00001-of-00002.gguf and Mistral-Large-Instruct-2411-Q4_K_M-00002-of-00002.gguf files.
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 64 -p 0 -n 128,256,512,1024,2048 -m /root/models/tests/Mistral-Large-Instruct-2411-Q4_K_M-00001-of-00002.gguf | model | size | params | backend | threads | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | -------------------: | | llama ?B Q4_K - Medium | 68.19 GiB | 122.61 B | BLAS,RPC | 64 | tg128 | 4.35 ± 0.00 | | llama ?B Q4_K - Medium | 68.19 GiB | 122.61 B | BLAS,RPC | 64 | tg256 | 4.33 ± 0.00 | | llama ?B Q4_K - Medium | 68.19 GiB | 122.61 B | BLAS,RPC | 64 | tg512 | 4.35 ± 0.00 | | llama ?B Q4_K - Medium | 68.19 GiB | 122.61 B | BLAS,RPC | 64 | tg1024 | 4.34 ± 0.00 | | llama ?B Q4_K - Medium | 68.19 GiB | 122.61 B | BLAS,RPC | 64 | tg2048 | 4.29 ± 0.00 | build: 51f311e0 (4753)
2. Mistral Large Instruct 2411 Q5_K_M
Using bartowski Mistral-Large-Instruct-2411-Q5_K_M-00001-of-00003.gguf, Mistral-Large-Instruct-2411-Q5_K_M-00002-of-00003.gguf and Mistral-Large-Instruct-2411-Q5_K_M-00003-of-00003.gguf files.
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 64 -p 0 -n 128,256,512,1024,2048 -m /root/models/tests/Mistral-Large-Instruct-2411-Q5_K_M-00001-of-00003.gguf | model | size | params | backend | threads | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | -------------------: | | llama ?B Q5_K - Medium | 80.55 GiB | 122.61 B | BLAS,RPC | 64 | tg128 | 3.75 ± 0.00 | | llama ?B Q5_K - Medium | 80.55 GiB | 122.61 B | BLAS,RPC | 64 | tg256 | 3.74 ± 0.01 | | llama ?B Q5_K - Medium | 80.55 GiB | 122.61 B | BLAS,RPC | 64 | tg512 | 3.74 ± 0.00 | | llama ?B Q5_K - Medium | 80.55 GiB | 122.61 B | BLAS,RPC | 64 | tg1024 | 3.74 ± 0.00 | | llama ?B Q5_K - Medium | 80.55 GiB | 122.61 B | BLAS,RPC | 64 | tg2048 | 3.70 ± 0.00 | build: 51f311e0 (4753)
3. Mistral Large Instruct 2411 Q6_K
Using bartowski Mistral-Large-Instruct-2411-Q6_K-00001-of-00003.gguf, Mistral-Large-Instruct-2411-Q6_K-00002-of-00003.gguf and Mistral-Large-Instruct-2411-Q6_K-00003-of-00003.gguf files.
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 64 -p 0 -n 128,256,512,1024,2048 -m /root/models/tests/Mistral-Large-Instruct-2411-Q6_K-00001-of-00003.gguf | model | size | params | backend | threads | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | -------------------: | | llama ?B Q6_K | 93.68 GiB | 122.61 B | BLAS,RPC | 64 | tg128 | 3.22 ± 0.00 | | llama ?B Q6_K | 93.68 GiB | 122.61 B | BLAS,RPC | 64 | tg256 | 3.24 ± 0.00 | | llama ?B Q6_K | 93.68 GiB | 122.61 B | BLAS,RPC | 64 | tg512 | 3.25 ± 0.00 | | llama ?B Q6_K | 93.68 GiB | 122.61 B | BLAS,RPC | 64 | tg1024 | 3.22 ± 0.00 | | llama ?B Q6_K | 93.68 GiB | 122.61 B | BLAS,RPC | 64 | tg2048 | 3.20 ± 0.00 | build: 51f311e0 (4753)
4. Mistral Large Instruct 2411 Q8_0
Using bartowski Mistral-Large-Instruct-2411-Q8_0-00001-of-00004.gguf, Mistral-Large-Instruct-2411-Q8_0-00002-of-00004.gguf, Mistral-Large-Instruct-2411-Q8_0-00003-of-00004.gguf and Mistral-Large-Instruct-2411-Q8_0-00004-of-00004.gguf files.
/root/llama.cpp/build/bin/llama-bench --numa distribute -t 64 -p 0 -n 128,256,512,1024,2048 -m /root/models/tests/Mistral-Large-Instruct-2411-Q8_0-00001-of-00004.gguf | model | size | params | backend | threads | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | -------------------: | | llama ?B Q8_0 | 121.33 GiB | 122.61 B | BLAS,RPC | 64 | tg128 | 2.61 ± 0.00 | | llama ?B Q8_0 | 121.33 GiB | 122.61 B | BLAS,RPC | 64 | tg256 | 2.61 ± 0.00 | | llama ?B Q8_0 | 121.33 GiB | 122.61 B | BLAS,RPC | 64 | tg512 | 2.64 ± 0.00 | | llama ?B Q8_0 | 121.33 GiB | 122.61 B | BLAS,RPC | 64 | tg1024 | 2.63 ± 0.00 | | llama ?B Q8_0 | 121.33 GiB | 122.61 B | BLAS,RPC | 64 | tg2048 | 2.61 ± 0.00 | build: 51f311e0 (4753)
Before all tests the cleaning cache commands were executed:
echo 0 > /proc/sys/kernel/numa_balancing echo 3 > /proc/sys/vm/drop_caches